Skills:




BBC News Classification Project
Project Overview
The goal of this project is to classify BBC news articles into five categories—business, entertainment, politics, sport, and tech—using machine learning techniques on text data. With 2225 labeled articles, the dataset is divided into 1490 training samples and 735 testing samples, and model performance is evaluated based on accuracy.
Objectives
- Develop Classification Models: Create models that can accurately categorize news articles into one of the specified five categories.
- Model Comparison: Explore two primary models—TF-IDF with traditional classifiers and NMF-based dimensionality reduction with supervised classification—to identify which model achieves higher classification accuracy.
- Optimize Performance: Use hyperparameter tuning to refine both models and maximize test accuracy.
Methodology
Data Preprocessing:
- Text Cleaning: Stopwords are removed, stemming is applied, and the cleaned text data is vectorized.
- Model Inputs: Two primary models, TF-IDF and NMF, are used for feature extraction and dimensionality reduction:
- Evaluation Metrics: Performance was evaluated using accuracy, precision, recall, and F1-score. These metrics are essential in understanding how well the model distinguishes between disaster and non-disaster tweets, particularly focusing on disaster-related content.
- TF-IDF (Term Frequency-Inverse Document Frequency) transforms text into a matrix representing word importance across the corpus.
- NMF (Non-negative Matrix Factorization) further reduces dimensionality, capturing essential topic structures in the text.
Model Training and Evaluation:
- TF-IDF with Classifiers: TF-IDF is combined with various supervised classifiers, including Random Forest and Logistic Regression, with hyperparameter tuning applied to optimize performance.
- NMF with Classifiers: NMF output is passed through classifiers such as Random Forest, which proved particularly effective. After tuning, the NMF-based model achieved high accuracy.
- Overall Balance: Precision, recall, and F1-scores were reasonably balanced, indicating reliable and consistent performance across both classes.
Evaluation and Results:
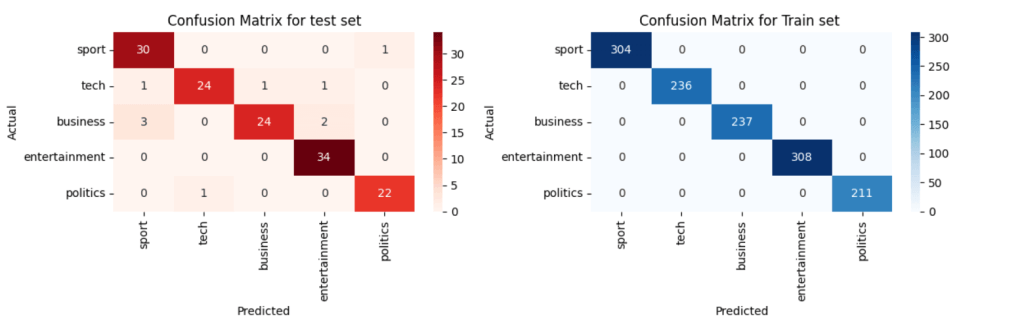
- The NMF model with hyperparameter tuning achieved 97.6% accuracy on the training set and 96.2% accuracy on the test set, showcasing its ability to generalize well across categories. These scores indicate robust performance on unseen data, and a classification report confirmed balanced accuracy across all categories.
- The TF-IDF model, while effective, did not reach the same accuracy levels as the NMF approach after tuning.
Comparison of TF-IDF and NMF Models
- TF-IDF Model: Provided a solid baseline for text classification but did not achieve the same level of refinement or dimensionality reduction as NMF.
- NMF Model: Captured deeper topic structures within articles, making it highly effective when combined with a tuned Random Forest classifier, resulting in superior accuracy for both training and test sets.
In summary, the NMF model proved to be the most effective for this classification task, achieving 96.2% accuracy on the test set, thus making it the recommended approach for similar text classification problems.